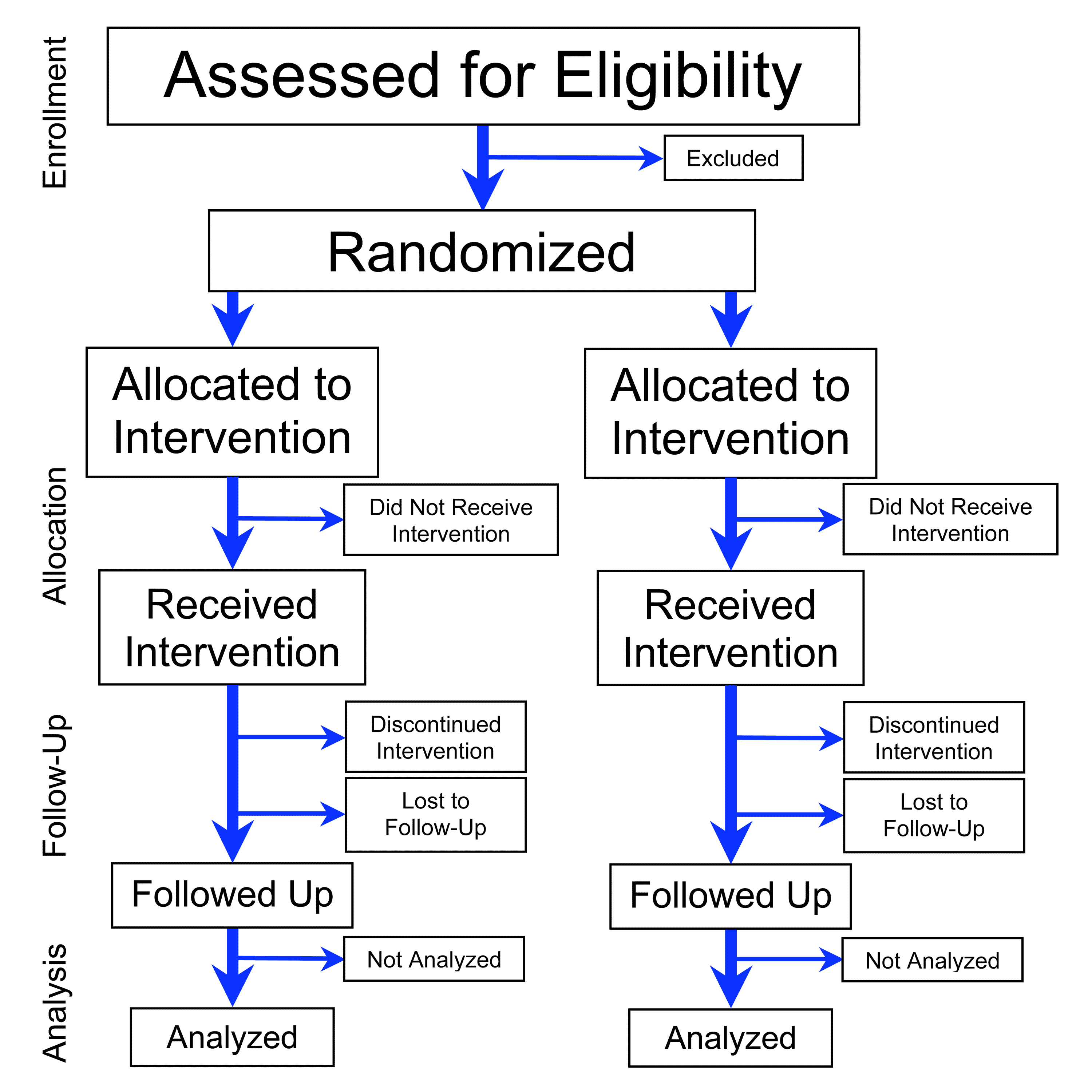
Randomized experiment
In science, randomized experiments are the experiments that allow the greatest reliability and validity of statistical estimates of treatment effects. Randomization-based inference is especially important in experimental design and in survey sampling.
Overview[edit]
In the statistical theory of design of experiments, randomization involves randomly allocating the experimental units across the treatment groups. For example, if an experiment compares a new drug against a standard drug, then the patients should be allocated to either the new drug or to the standard drug control using randomization.
Randomized experimentation is not haphazard. Randomization reduces bias by equalising other factors that have not been explicitly accounted for in the experimental design (according to the law of large numbers). Randomization also produces ignorable designs, which are valuable in model-based statistical inference, especially Bayesian or likelihood-based. In the design of experiments, the simplest design for comparing treatments is the "completely randomized design". Some "restriction on randomization" can occur with blocking and experiments that have hard-to-change factors; additional restrictions on randomization can occur when a full randomization is infeasible or when it is desirable to reduce the variance of estimators of selected effects.
Randomization of treatment in clinical trials pose ethical problems. In some cases, randomization reduces the therapeutic options for both physician and patient, and so randomization requires clinical equipoise regarding the treatments.