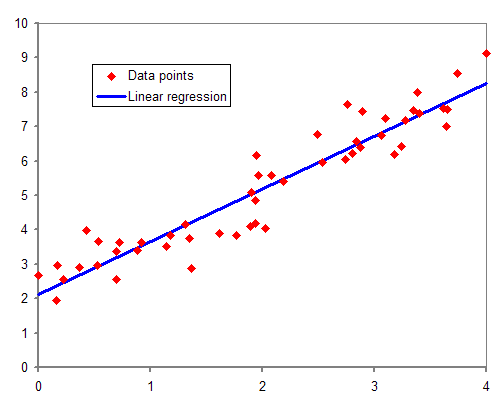
Regression analysis
In statistical modeling, regression analysis is a set of statistical processes for estimating the relationships between a dependent variable (often called the 'outcome' or 'response' variable, or a 'label' in machine learning parlance) and one or more independent variables (often called 'predictors', 'covariates', 'explanatory variables' or 'features'). The most common form of regression analysis is linear regression, in which one finds the line (or a more complex linear combination) that most closely fits the data according to a specific mathematical criterion. For example, the method of ordinary least squares computes the unique line (or hyperplane) that minimizes the sum of squared differences between the true data and that line (or hyperplane). For specific mathematical reasons (see linear regression), this allows the researcher to estimate the conditional expectation (or population average value) of the dependent variable when the independent variables take on a given set of values. Less common forms of regression use slightly different procedures to estimate alternative location parameters (e.g., quantile regression or Necessary Condition Analysis[1]) or estimate the conditional expectation across a broader collection of non-linear models (e.g., nonparametric regression).
Regression analysis is primarily used for two conceptually distinct purposes. First, regression analysis is widely used for prediction and forecasting, where its use has substantial overlap with the field of machine learning. Second, in some situations regression analysis can be used to infer causal relationships between the independent and dependent variables. Importantly, regressions by themselves only reveal relationships between a dependent variable and a collection of independent variables in a fixed dataset. To use regressions for prediction or to infer causal relationships, respectively, a researcher must carefully justify why existing relationships have predictive power for a new context or why a relationship between two variables has a causal interpretation. The latter is especially important when researchers hope to estimate causal relationships using observational data.[2][3]
History[edit]
The earliest form of regression was the method of least squares, which was published by Legendre in 1805,[4] and by Gauss in 1809.[5] Legendre and Gauss both applied the method to the problem of determining, from astronomical observations, the orbits of bodies about the Sun (mostly comets, but also later the then newly discovered minor planets). Gauss published a further development of the theory of least squares in 1821,[6] including a version of the Gauss–Markov theorem.
The term "regression" was coined by Francis Galton in the 19th century to describe a biological phenomenon. The phenomenon was that the heights of descendants of tall ancestors tend to regress down towards a normal average (a phenomenon also known as regression toward the mean).[7][8]
For Galton, regression had only this biological meaning,[9][10] but his work was later extended by Udny Yule and Karl Pearson to a more general statistical context.[11][12] In the work of Yule and Pearson, the joint distribution of the response and explanatory variables is assumed to be Gaussian. This assumption was weakened by R.A. Fisher in his works of 1922 and 1925.[13][14][15] Fisher assumed that the conditional distribution of the response variable is Gaussian, but the joint distribution need not be. In this respect, Fisher's assumption is closer to Gauss's formulation of 1821.
In the 1950s and 1960s, economists used electromechanical desk calculators to calculate regressions. Before 1970, it sometimes took up to 24 hours to receive the result from one regression.[16]
Regression methods continue to be an area of active research. In recent decades, new methods have been developed for robust regression, regression involving correlated responses such as time series and growth curves, regression in which the predictor (independent variable) or response variables are curves, images, graphs, or other complex data objects, regression methods accommodating various types of missing data, nonparametric regression, Bayesian methods for regression, regression in which the predictor variables are measured with error, regression with more predictor variables than observations, and causal inference with regression.

The independent variables, which are observed in data and are often denoted as a vector (where denotes a row of data).


The dependent variable, which are observed in data and often denoted using the scalar .

The error terms, which are not directly observed in data and are often denoted using the scalar .

In practice, researchers first select a model they would like to estimate and then use their chosen method (e.g., ordinary least squares) to estimate the parameters of that model. Regression models involve the following components:
In various fields of application, different terminologies are used in place of dependent and independent variables.
Most regression models propose that is a function (regression function) of and , with representing an additive error term that may stand in for un-modeled determinants of or random statistical noise:
The researchers' goal is to estimate the function that most closely fits the data. To carry out regression analysis, the form of the function must be specified. Sometimes the form of this function is based on knowledge about the relationship between and that does not rely on the data. If no such knowledge is available, a flexible or convenient form for is chosen. For example, a simple univariate regression may propose , suggesting that the researcher believes to be a reasonable approximation for the statistical process generating the data.
Once researchers determine their preferred statistical model, different forms of regression analysis provide tools to estimate the parameters . For example, least squares (including its most common variant, ordinary least squares) finds the value of that minimizes the sum of squared errors . A given regression method will ultimately provide an estimate of , usually denoted to distinguish the estimate from the true (unknown) parameter value that generated the data. Using this estimate, the researcher can then use the fitted value for prediction or to assess the accuracy of the model in explaining the data. Whether the researcher is intrinsically interested in the estimate or the predicted value will depend on context and their goals. As described in ordinary least squares, least squares is widely used because the estimated function approximates the conditional expectation .[5] However, alternative variants (e.g., least absolute deviations or quantile regression) are useful when researchers want to model other functions .
It is important to note that there must be sufficient data to estimate a regression model. For example, suppose that a researcher has access to rows of data with one dependent and two independent variables: . Suppose further that the researcher wants to estimate a bivariate linear model via least squares: . If the researcher only has access to data points, then they could find infinitely many combinations that explain the data equally well: any combination can be chosen that satisfies , all of which lead to and are therefore valid solutions that minimize the sum of squared residuals. To understand why there are infinitely many options, note that the system of equations is to be solved for 3 unknowns, which makes the system underdetermined. Alternatively, one can visualize infinitely many 3-dimensional planes that go through fixed points.
More generally, to estimate a least squares model with distinct parameters, one must have distinct data points. If , then there does not generally exist a set of parameters that will perfectly fit the data. The quantity appears often in regression analysis, and is referred to as the degrees of freedom in the model. Moreover, to estimate a least squares model, the independent variables must be linearly independent: one must not be able to reconstruct any of the independent variables by adding and multiplying the remaining independent variables. As discussed in ordinary least squares, this condition ensures that is an invertible matrix and therefore that a unique solution exists.























Deviations from the model have an expected value of zero, conditional on covariates:

The variance of the residuals is constant across observations ().
homoscedasticity
The residuals are with one another. Mathematically, the variance–covariance matrix of the errors is diagonal.
uncorrelated
By itself, a regression is simply a calculation using the data. In order to interpret the output of regression as a meaningful statistical quantity that measures real-world relationships, researchers often rely on a number of classical assumptions. These assumptions often include:
A handful of conditions are sufficient for the least-squares estimator to possess desirable properties: in particular, the Gauss–Markov assumptions imply that the parameter estimates will be unbiased, consistent, and efficient in the class of linear unbiased estimators. Practitioners have developed a variety of methods to maintain some or all of these desirable properties in real-world settings, because these classical assumptions are unlikely to hold exactly. For example, modeling errors-in-variables can lead to reasonable estimates independent variables are measured with errors. Heteroscedasticity-consistent standard errors allow the variance of to change across values of . Correlated errors that exist within subsets of the data or follow specific patterns can be handled using clustered standard errors, geographic weighted regression, or Newey–West standard errors, among other techniques. When rows of data correspond to locations in space, the choice of how to model within geographic units can have important consequences.[17][18] The subfield of econometrics is largely focused on developing techniques that allow researchers to make reasonable real-world conclusions in real-world settings, where classical assumptions do not hold exactly.
Although the parameters of a regression model are usually estimated using the method of least squares, other methods which have been used include: